- Published on
Machine Learning for Health Data
- Authors
- Name
- Ally Salim Jr
- @3210jr


Considerations When Using Machine Learning for Health Data
Introduction
It should be fairly clear by now that this truly is the century of automation, scale, and automation at scale. A lot of this progress has come as a result of the fact that, for the first time in recorded history, we have the computation power, a growing skilled talent pool and data/information needed to build (relatively) smart technologies. This is the Artificial Intellligence and Machine Learning revolution.
Often confused with one another, Artificial Intelligence is more abstract and can be seen as "intelligence exhibited by computers (non natural)" while Machine Learning is a method of achieving the computer intelligence through learning from examples (data).
Healthcare is also no stranger to attempts at improving health decision making through ML and other AI approaches. Since the 1950s, beginning with the book "Computers and Intelligence" by Alan Turing, many of us have been working on bringing some of this intelligence to medicine. Even throughout the infamous AI winters of 1970s to 2000s, small communities worked on the illusive problem.
These advances have come with their fair share of concerns and considerations that must be kept in mind when applying Machine Learning to health data. This article discusses some of these.
On Data & ML
Collected data, in the case of machine learning, should be thought of as "examples" for the machine to learn from. When data is "labeled", i.e: this is the lab result of a Malaria patient, the lab result is the example question and the "Malaria" diagnosis is the example answer.
Note: The rest of this article will focus exclusively on structured and tabular clinical data, as opposed to unstructured data such as images, videos, audio and written language.
Size matters
In Machine Learning and Data Science, like in many other aspects of life, size matters. The size of your dataset determines how much you can do and learn from it. This is the set of examples and training materials you have for training your computer to solve your problem. Assuming your data is representative of your problem space, the more examples you have the more you can expect from your learning algorithms (usually).
Consideration: Medical/clinical data is notoriously difficult and expensive to collect to satisfy the requirements of algorithms to achieve acceptable performances. The very diverse characteristics of diseases, humans, environments, histories, cultures, etc make the requirements on collecting complete data (to generalize better) almost unmeetable.
Good data, bad data, irrelevant data, and missing data
It helps to think of data as belonging to one of 4 buckets, as gross a simplification as it is: good, bad, irrelevant and missing/absent data.
These four categories help draw broad strokes for communication purposes and so we are going to stick with them for now.
Good data: This is data that has the "good" characteristics we are looking for, namely:
- It is relevant: The data is helpful to solve the problem we have.
- It is clean or it can be cleaned: There are no typos, inconsitencies, clerking errors, etc, or we can get to that state.
- It is ethical and responsible: The data was collected ethically, and we obtained it using the correct processes.
- It is unbiased: Maybe the hardest line item, unbiased data contains all the needed features, collected from all the groups of people, in all the necessary contexts. Bias is extremely difficult and expensive to mitigate.
- It is complete: The dataset is representative of the real setting and contains all necessary variations and perturbations that are normally present.
- and more ...
Bad data: After defining good data, bad data is pretty easy to define with our loose standards. "Bad" data is data that is not "good".
Irrelevant data: Not all data is useful for the problem you are trying to solve. In the ML space, we often hear proclamations such as: "Company X has tons of data" or "We have a lot of data in our databases". From my experience, it is more often than not that the "data" in question here is not relevant to the problem in hand.
When creating a malaria diagnosis model or algorithm, recent social media data is unlikely useful at all. (An arguement can be made in this case for using recent social media data to approximate the prevalence of Malaria, but as you can probably imagine, this isn't going to be fun for anyone!)
Missing data: Missing data keeps many data scientists awake at night - it is the stuff of nightmares. However, in this case, we are talking about something much worse and insidious, "uncollected data".
Unlike the common occurance of missing fields in a dataset, uncollected data is missing from the dataset simply because it was not collected in the first place. This is a limitation on how much the data truly represents the problem space it is meant to solve.
Context: Machine Learning models approximate the mapping (arrows) from an input to an output.
e.g 1: You show the computer examples of all the people you could find with malaria and it associates the symptoms/signs with the diagnosis of malaria.
e.g 2: You show the computer examples of all the people in your database who received loans, and associate their characteristics to whether or not they defaulted on their loans.
Missing ear pain in infants:
Albeit a trivial example, this is an extremely clear one. Over the years, we have collected about 20,000 pediatric patient visits across Tanzania, but none of the infants with an ear infection have the symptom of "ear-pain". This is because they cannot say that they have "ear-pain" or indicate it in any way.
A statistical model will therefore not learn the association between the symptom and diagnosis, preventing generalization to populations that "can" indicate their ear pain (like toddlers and adults or mutant babies that are born with full communication skills).
Consideration: Really look at your data and bring in experts to clearly identify deficiencies in your datasets. If you choose to move on with current deficiencies, do so knowing what they are.
Data & concept drift
The world, being as dynamic as it is, is always changing. These changes could be seasonal, gradual, or sudden and have a great effect on Machine Learning algorithms.
Data drift: Over time, the same inputs have now changed and the distributions of the variables are now meanigfully different. An example of this is that the types of patients now visiting the hospital are different from those in your taining data.
Concept drift: While data drift is a change in the input variables, concept drift is when the value being predicted changes and even the relationships between the input and the output changes. An example of this is the changing prevalence of a disease in a hospital.
Without going into too much detail, here is an excellent illustration from Twitter:

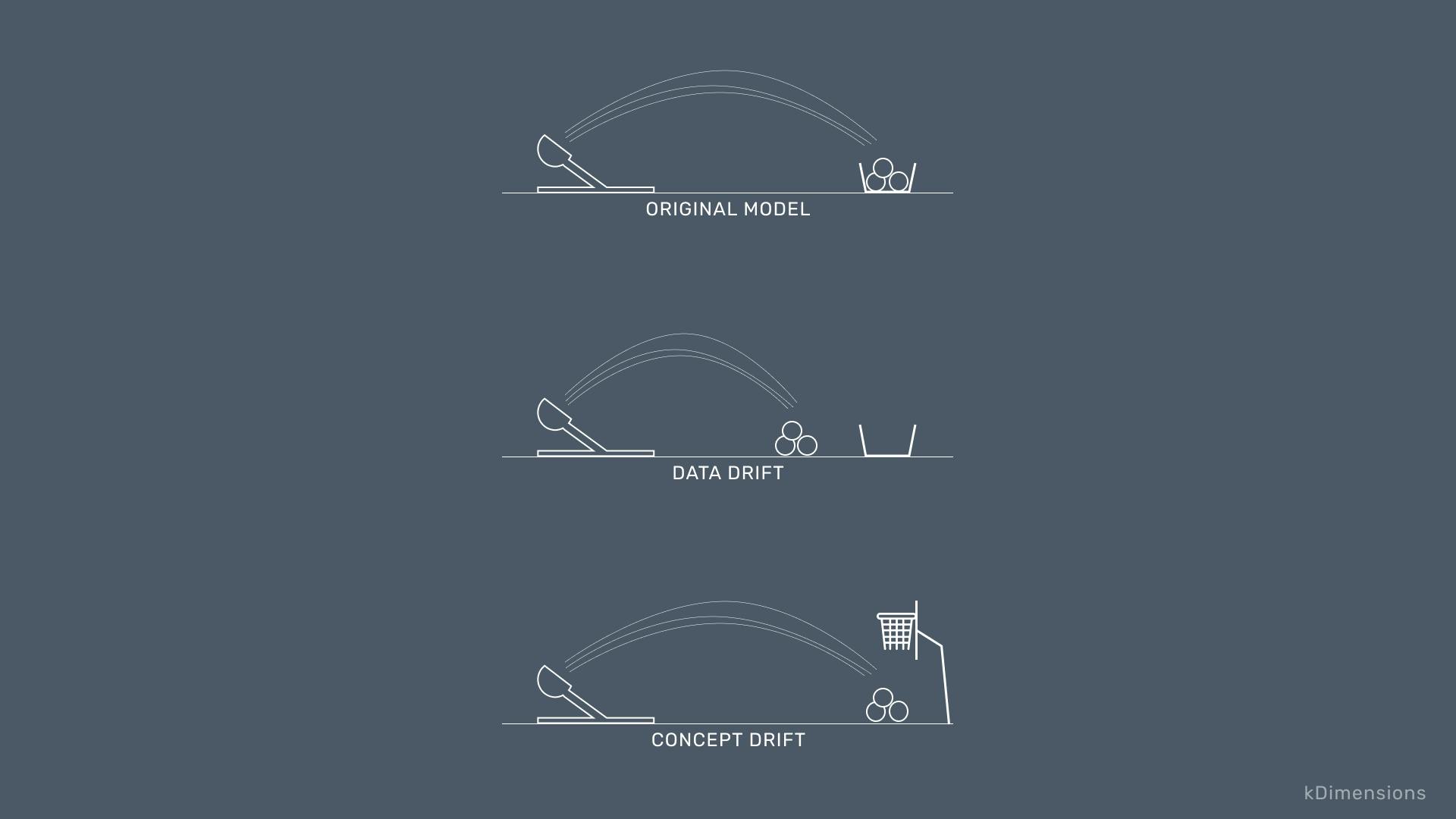
Credit: @kDimensions
Better the assumptions you know, than the assumptions you don't
More often than not, explicit is better than implicit. This is also the case in the assumptions we constantly make when applying Machine Learning algorithms to our data. A strength of expert systems (an alternative to ML for AI) is that they are explicit and often it is easy to see all the assumptions laid out right in front of you. If the expert system says: if fever then malaria, you can make out the 1:1 assumption there.
Often, when using Machine Learning algorithms, many assumptions are made for you since these algorithms are more interested in fitting to the data than in solving the problem. You as the data scientist / engineer are responsible for the correct definition and application of the problem. Examples of assumptions often made are:
- Your data is Independent and Identically Distributed (iid): each data point is independent of another one you collected, and collecting one does not affect the other ones.
- There is no relationship between the features: In your training examples, the age column is not related to the sex column (probably okay) or the smoking column (probably not okay).
- Linear relationships: There is a linear relationship between the inputs and the outputs (target) and your model can be described by the form:
Y = AX1 + BX2 + ... + c. - Independent variables are Normally Distributed: Even though the normal distribution is every mathematicians ideal distribution (a God send really), many ML techniques require you to make this assumption.
- and many more ...
Consideration: Be clear that you are always making assumptions. When you don't think you are making assumptions, its likely because they are being made for you. In either way, Machine Learning models dictate the assumptions you are to make and dealing with this requires care and thorough testing.
Correlation is very helpful, so is causation.
All statistics students have probably heard the mantra: "Correlation does not equal causation". What we see from ML is a learning of the correlations between the variables and the target variable (the thing we are trying to predict).
Learning from correlations has gotten us to where we are now, but often times in medicine we are trying to ask "what if questions". Examples of these are:
- What if we give the patient drug X as opposed to drug Y?
- What if our patient has both Malaria and Congestive Heart Failure?
- What would be the effect of distributing mosquito nets in this area?
These are difficult questions as they live in the counterfactual space, and cannot be answered by models we build using correlations.


Credit: https://twitter.com/mribeirodantas/status/1444403274220769285
This is a very big downside of learning from data and machine learning in general, but is an active field of research at the moment of this writing.
Consideration: When learning from data alone, it is not possible (yet?) to learn the direction of causality. Whenever possible, incorporate known causal knowledge from experts. This might limit your selection of models but might be a trade-off you are willing to make.
Constantly starting from scratch
Typical Machine Learning approaches assume the data is all encompasing and we don,t know anything about the problem space before we begun. Therefore, we take our data and ask the model to learn everything from it, and everytime we do this, we start building knowledge from scratch.
In health and medicine, there exists a large body of literature that can be used as the body of knowlege and information to build on and leverage. Most ML techniques have limited or no room to incorporate existing knowledge.
Consideration: Prior knowledge is an invaluable resource. It helps mitigate issues with causation, data availability and quality, and bias (could be harmful with bad actors). If at all possible, choose to incorporate prior knowledge. Consider bayesian and expert system approaches too.
Reach Out to Us
To learn more about our work, or if you are interested in working together, please reach out to us through our website or follow us on social media!
To contact us directly visit our site: elsa.health/contact