- Published on
Peer-to-Peer, Decentralized Technology for Healthcare
- Authors
- Name
- Megan Allen
- @mayghen92


What is a Peer-to-Peer Network?
When developing software solutions, there are two main potential architectures that can be used to achieve information exchange: client–server and peer-to-peer (P2P). In client–server architecture, a central server connects all clients, and the clients exchange data directly with the server. In a P2P network, clients (also called "peers") directly communicate directly with each other, without the need for a central server [1] [2]. It is also worth noting that hybrid approaches have grown in popularity as a way to get the best of both worlds.
With the P2P approach, peers on the network are equal and, depending on permission and access rules, each peer provides access to its resources and data [3]. This is distinct to a traditional, centralized server-client architecture, where there is a single processing and data storage resource.
P2P networks are "popular subjects for research because they offer an easy strategy for managing distributed resources, such as storage space or processing power" [4]. They are also being used more and more in the commercial space, powering chat platforms (Tox Chat, Retroshare, etc.), video conferencing, video streaming (PeerTube, DTube), finances, etc. In healthcare, P2P personal health records have been proposed to allow patients to maintain a complete health record and have increased control and ownership over their data [5] [6].
Use Case: A Connected Facility Workflow
Our healthcare tools for Care and Treatment Centers (CTCs) work on a peer-to-peer network that allows facilities to store their own data, while also sharing data to other CTCs when needed. All data collected regarding patients and clinic visits is stored in the device that was used to record it (phone at each facility that is running the Elsa platform), and then it is propagated to all the connected devices that are requesting/subscribed to that specific information (example: patient records).

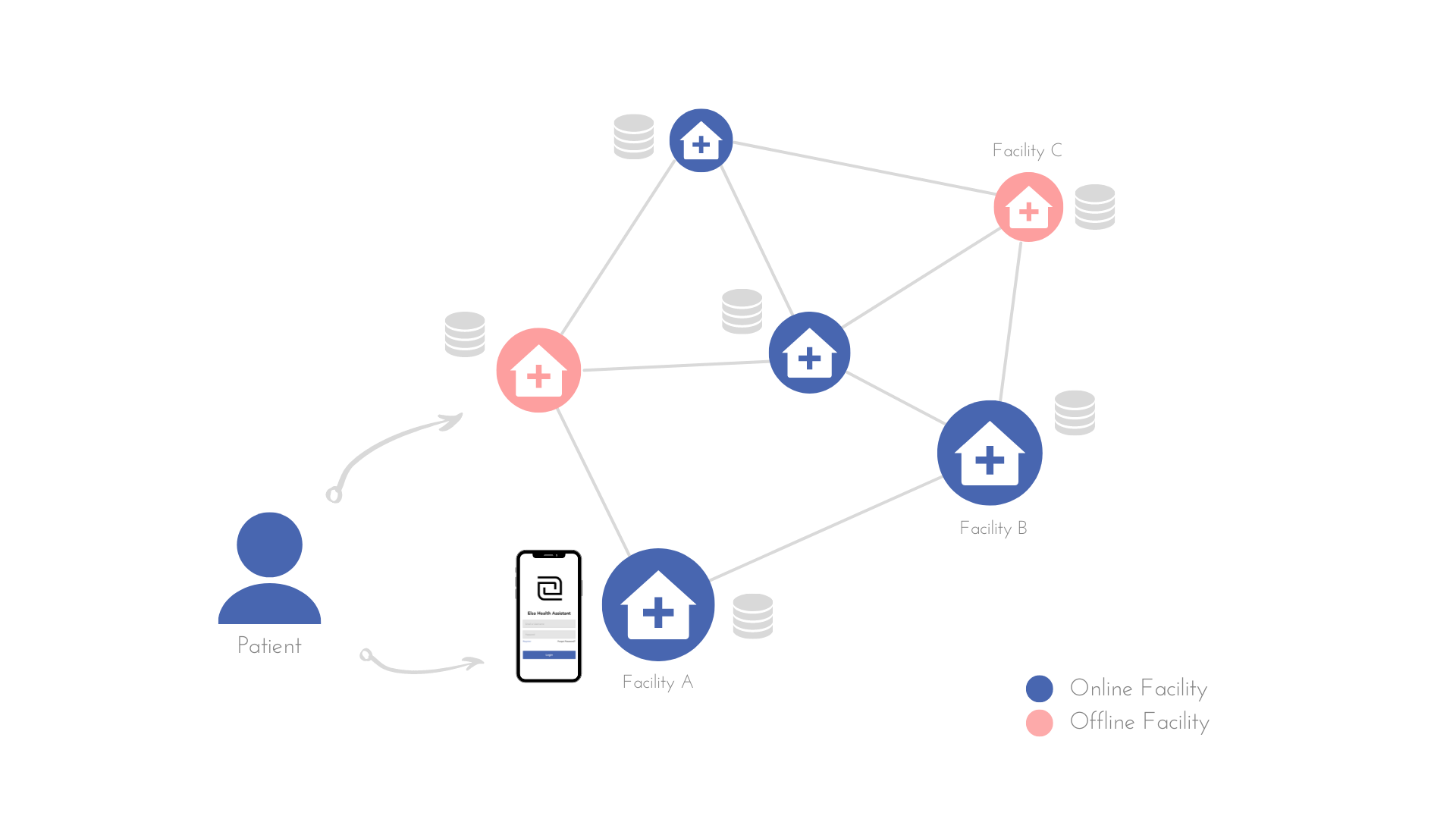
The graphic above shows how the CTCs are connected in this use case; blue nodes are online and red nodes are offline. A patient is registered into the system through their primary facility, and our tools empower clinicians with patient management and decision support.
If a patient goes to a different facility to pick up their medication or get tests, that facility is able to pull up the patient’s record stored in the network and record the patient’s visit. If a patient visits a facility that is offline, other facilities will not be able to get the data from them immediately (see eventual consistency below); however, when network availability is restored, other facilities can request and access the data.
You can see how this peer-to-peer network works in this video.
Benefits of the Approach
P2P networks have several advantages over client-server architectures. First, they are self-scalable and can grow up to hundred of thousands of peers [7]. Additionally, instead of being concentrated on a single server, compute and storage costs are shared by each of the peers in the network. This significantly reduces the cost of large-scale projects that require data to be stored and shared across devices/ facilities.
P2P networks also have offline capabilities and are resilient against network failures [7], making them useful in even the most remote settings.
Lastly, they can have privacy advantages over client-server architectures. For example, given the distributed nature of the data, it is much harder to compromise the entire network of data. Additionally, given that authentication and data encryption is also not centralized, it is much harder to gain access to more than one account at a time.
Eventual Consistency
CAP Theorem dictates that for data storage systems there is a tradeoff between Consistency, Availability and Partition Tolerance, and that you can not have more than two of these guarantees [8]. Our platform is an AP-first network focusing on Availability and Partition Tolerance while promising Eventual Consistency. This means when a new patient is seen at Facility X, the rest of the network will not hear about it immediately, but eventually.
Here “eventually” is typically the next time Facility X is online and connected to the larger CTC network of devices. For example, when a patient from Facility X goes to Facility Y, the records at Facility X will be updated so that the clinician can see exactly which facility they went to, when they went, if they had any symptoms, and what medications they were prescribed. All of this happens eventually as both facilities come online - they do not have to be online at the same time.
Elsa uses Convergent Replicated Data Types (CRDTs), allowing all peers that request information to be updated independently and concurrently without much effort from the rest of the devices [9].
Challenges of This Approach
A key challenge is related to eventual consistency - without forcing all devices to be online at the same time, it is not possible to guarantee that the data someone has at this instance will be all the data that was generated up until this point.
When looking at reports and summaries, there will always be a small chance one of the devices that is still offline has not yet synchronized their data. We have found this to be a very small price to pay for the support of an offline-first architecture, and is relatively easy to mitigate through scheduled synchronization activities and reporting time-stamps of the most recent synchronizations.
Connect with Us
If you're interested in collaborating with us to improve, deploy, and/or scale this technology, we'd love to chat about how to make that possible!
If you're a clinician or a developer and are interested in contributing to this work, we would love to have you join our community! Clinical friends can contribute through our Open Health Platform. Technical friends can see our open source code and documentation on Github here and here.